과제 선 제출
| 과제 본문 링크 | |||
| 1주차 (1/6 ~ 1/12) |
Chapter 01 ~ 03 | p. 51의 확인 문제 3번, p. 65의 확인 문제 3번 풀고 인증하기 |
p. 100의 스택과 큐의 개념을 정리하기 |
프로그램이 실행되려면 반드시 메인메모리에 저장되어 있어야 합니다.
0b1101을 음수로 표현한 값은 0 b0011입니다.
스택: 후입선출 LIFO last in first out
프로그램 흐름에 있어 스택 구조로 프로그램이 동작. 특히 동작은 함수로 구현되는데 동작을 수행 시 함수가 콜 될 때는 푸시를 계속 연달아 넣고, 리턴이 일어날 때 팝으로 데이터반환이 일어나 다음 동작을 완료함.
큐: 선입선출 FIFO first in first out
프로세스 스케쥴링에 사용. cpu는 하나의 동작만을 멀뚱히하고 있지 않는다. 멀티작업을 수행하는데 이때 먼저 스케쥴링이 잡힌 사람은 사이클 이후에 다시 순서대로 가는 게 일반적. 그때 당장에 필요한 데이터중요한 스택방식과는 차별적으로 먼저 들어간 순서를 지켜주는 스케쥴링에서는 큐가 사용.
Chapter 01 컴퓨터 구조의 시작
들어가기 전에
프로그래밍 언어만 알아서는 좋은 개발자 못된다 - 저자 -
학습 목표
- 왜 컴퓨터구조를 알아야 할까?
1. 개발한 소스코드가 돌아가는 건 컴퓨터. 문제가 발생했을 때 컴퓨터 구조단위로 나누어 분석해 볼 수 있음
2. HW + SW 둘 다 잘 아는 개발자라면 성능, 용량, 비용을 진단할 수 있음 - 컴퓨터 구조를 그릴 수 있나?
더보기내가 그린 그림
01-1 컴퓨터 구조를 알아야 하는 이유
1. 문제해결
소스코드만 짤 줄 안다고 개발이 끝나는 게 아니다.
만약 똑같은 소스코드인데 컴퓨터가 동작 안 하면 기도를(난 그랬던 거 같다…)할 수도 없고 분석을 해야 될 거 아니야.
컴퓨터 구조를 아는 자와 모르는 자의 차이는 소스코드를 넘어 컴퓨터 단위까지 분석이 되냐의 차이이다.
실제 기업들에선 항상 필수요건으로 내거는 게 컴퓨터 아키텍처이다.
2. 성능, 용량, 비용
컴퓨터 구조에 익숙해지고 해당 부품들이 어느 정도 성능을 낼지를 아는 것은 용량과 비용 선택에 영향을 미친다. 컴퓨터구죠 배우고 비용 아끼자
확인 문제
1. 2번은 직접적이라 볼순 없다
2. 미지의 대상, 분석의 대상
01-2 컴퓨터 구조의 큰 그림
핵심 키워드
- 데이터 : 컴퓨터가 다루는 그 자체
- 명령어 : 그래서 데이터를 어떻게 할 건데? 를 정하는 게 명령어
- cpu : 그런 명령어를 만들고 데이터를 해석하고 등 동작 컨트롤타워가 cpu
- 보조기억장치 :상대적으로 큰 용량으로 방대한 데이터들을 논리에 맞게 저장하고 있음
- 입출력장치 : 사용자가 컴퓨터와 대화하기 위한 수단
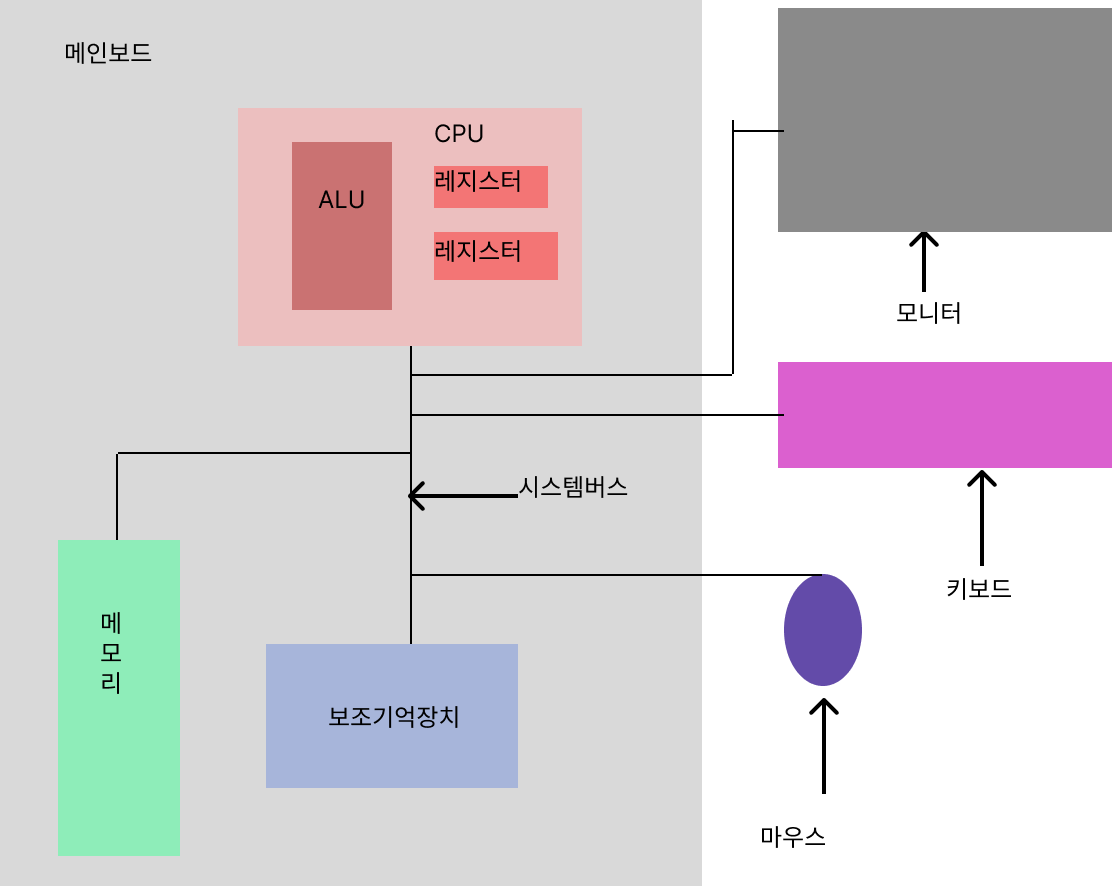
- 시스템 버스 : 메인보드에 위치하여 각 장치들이 소통하는 통로
컴퓨터 구조를 설명하기 위한 크게 2가지
- 컴퓨터가 이해하는 정보
- 대표장치 4가지
컴퓨터가 이해하는 정보
데이터와 명령어로 나뉨.
데이터: 동작을 위한 정적 재료
명령어: 동작 그 자체
프로그램: 명령어와 데이터가 짬뽕됨
컴퓨터의 4가지 핵심 부품
어떤 종류의 컴퓨터가 되었든 다음의 4가지는 있을 수밖에 없음
CPU, 메모리, 보조기억장치, 입출력장치
메모리
현재 실행되고 있는 프로세스에 필요한 명령어와 데이터들이 올라가져 있는 저장 장치
RAM과 ROM이 있음.
ROM은 Bios Chip이 대표 사례 Read Only Memory
RAM은 운영체제가 주로 동적으로 사용하는 주기억 장치 그 자체 Random Access Memory
왜 랜덤이냐… 실제로 항상 깔쌈하게 일렬로 정돈되어 저장되고 사용되는 건 불가능!!
왜냐 데이터의 크기(차지하는 공간)도 다 다르고 명령어의 줄도 다른데 하물며 사용하여 더 이상 사용하지 않을 경우엔 빠르게 메모리를 비워줘야 됨. 즉 ROM과 달리 쓰고 읽기를 할 때 Random 하게 사용될 수밖에 없음. 그렇지만 그게 에러는 아님. 왜냐하면 주소라는 개념을 항시 사용하여 원하는 주소가 해시되어 마치 일렬로 저장된 듯이 프로세스가 돌아가기 때문!!
cpu
컴퓨터의 두뇌
ALU: 데이터와 명령어를 읽어서 해석하고 어떻게 저장하면 될지도 다 계산 때려주는 놈
제어장치: ALU가 만든 명령어를 해석하여 어디에 신호를 보내면 될지를 컨트롤
레지스터: ALU가 계산하기 위해 필요한 정말 빠르고 용량이 적은 저장장치
메모리 + CPU
프로세스를 시작시키면 메모리위에 올라가 있는 명령어와 데이터를 토대로 동작이 돌아가게끔 되어있음. 주소를 참조하여 데이터와 명령어가 만드는 또 주소로 참조하는 식으로 계속 사이클이 돌아감
보조기억장치
휘발성인 RAM보다 속도는 느리지만 용량은 크고 영구 저장능력이 있는 저장장치
통찰
연산에 참여하지 않고 데이터의 송수신이 일어난다는 점에서 입출력장치 아니냐는 견해가 있지만, 메모리와 긴밀하게 소통하여 같이 묶지는 않는다.
입출력장치
데이터 송수신이 일어나 사용자와 컴퓨터가 소통할 수 있는 장치
메인보드와 시스템버스
부품들이 통신할 수 있게 연결하는 역할이 시스템 버스
시스템버스는
주소버스, 데이터버스, 제어버스
3가지로 나누고 자기가 가진 이름이 곧 각자가 다루는 타입과 일치함.
확인문제
1. 명령어 데이터
2. 3번
3. 메인메모리 or 주기억장치
4. 1-ㄴ 2-ㄱ
5. 1번
CH02 데이터
컴퓨터는 0과 1로만 모든 것을 표현. 그런데 0과 1로 숫자 문자 이모티콘 그림 등등을 대체 어떻게 표현하는 거지?
학습 목표
- 컴퓨터가 이해하는 정보 단위
- 0과 1로 다양한 숫자를 표현하는 방법
- 0과 1로 다양한 문자를 표현하는 방법
02-1 0과 1로 숫자를 표현하는 방법
컴퓨터가 이해하는 정보의 단위
0 1 0 1로만 모든 걸 표현한다는 것은 다 이유가 있다. 논리 회로에서 스위치 온과 스위치 오프를 표현하는 게 0과 1이기 때문이다. 저항이 없으면 1(전류 통함) 저항이 있으면 0(전류차단) 이런 느낌
스위치 한 개로 표현할 경우의 수는 2가지
스위치 2개로 표현할 경우의 수는 4가지
스위치 3개로 표현할 경우의 수는 8가지
따라서 2^n개를 만족하는 것
여기서 이러한 스위치 한 개의 단위를 비트라고 한다.
즉 n비트는 2^n개의 경우의 수를 가짐.
그런데 비트 단위만 있다면 수억 개의 비트로 이루어진 프로그램의 경우와 이걸 표현하기엔 너무 힘들다. 그래서 비트를 가지고 여러 단위가 만들어짐.
8bit = 1byte
그리고 byte를 이용하여 1000byte = 1kB
1000kB = 1MB
1000MB = 1GB
1000GB = 1TB
참고
1024byte = 1 KiB 즉 1024배 단위로 증가하는 경우와 표기 자체가 다르다.
워드: CPU에 의존하는 단위 개념. CPU가 한 번에 처리가능한 데이터 블록의 단위가 있다. CPU라고 막 1비트씩 한땀 한땀 작업하는게 아니라 블럭 떠다가 뭉텅뭉텅 작업한다. 16비트 32비트 64비트 컴퓨터라고 할 때 각각의 워드 단위를 의미함.
이진법
비트의 조합으로 데이터를 표현하다고 했는데 해당 비트 개념을 수학적으로 표현하여 인간 및 컴퓨터가 연산하는 방식이 이진법이다. 컴퓨터의 논리를 가장 직접적으로 표현하는 방법
십육 진법
그런데 비트단위로 모든 데이터를 저장하고 표현하는 건 알겠고, 해당 비트 개념을 수학적으로 표현하기 가장 적합한 게 이진법인 것도 알겠는데 이진법만으로 수학적인 계산을 표현하기엔 힘들다. 그래서 등장한 게 16진법. 2진법을 아주 쉽게 변환할 뿐만 아니라 0~9, A~F 만으로 표현이 가능하기에 용이
2진법 <-> 16진법
2진법 4자리는 총 2^4개 16가지를 표현할 수 있으며 이는 16진법 1자리와 동일하다.
데이터 변환에서 음수의 개념
음수를 표현할 때에는 보수의 개념을 차용한다.
보수: 합이 어느 일정한 수가 되게 하는 수.
2의 보수: 합이 2가 되게 하는 수.
편의상 2의 보수라고 하는데 실상 개념은 2^n승 보수이다. 이게 뭔 말이냐…
어떤 수 0b1010 이 있다고 할 때 해당 수의 음수는 0b10000의 보수로 음수를 표현함.
1의 2의 보수는 1이다. 0의 2의 보수는 2이고.
여기서 말하는 A의 2^n의 보수란 2^n자리에 올림이 일어나게 만드는 수가 보수라는 거고 해당 보수를 음수라고 하겠다는 것.
음수와 보수는 엄연히 다른데 보수를 음수로 차용한 데에는 다 이유가 있다. 더했을 때 하나 삐져나가게 되는데 그러면 0이니까. 뭔 소리냐면
데이터에게 주어진 자릿수가 총 4자리라면 0010일 때 보수인 1110을 더해버리면 1/0000 이 되는데 올려진 1을 표현할 방법이 없으니 자연스레 0이 되고 a+(-a) = 0이 이까 2^자릿수+1의 보수로 음수를 표현하면 되겠다는 아이디어.
보수를 만드는 공식은 0과 1을 뒤집은 뒤에 1을 더해줌으로써 쉽게 만들어진다는 장점도 있다.
마무리 직접 쓰기
5가지 키워드
비트:
데이터를 표현하는 가장 작은 단위
바이트:
비트의 8배. 바이트를 이용하여 여러 단위를 만들 수 있음.
이진법:
비트를 표현하기 가장 좋은 진법
2의 보수:
음수를 표현하기 가장 좋은 방법
십육 진법:
이진법을 사람의 언어로 표현하기 가장 좋은 방법
확인 문제
1. 2
2. 4
3. 0011
4. 1101 1010
5. 1
02-2 0과 1로 문자를 표현하는 방법
문자 집합과 인코딩 디코딩
어찌 되었든 0과 1로 표현되는 건 바꿀 수 없어. 그럼 해당 0과 1 조합에 이건 문자야 라고 약속을 해주면 되는 것.
문자의 이진수 값 약속: 문자 집합
문자를 문자 집합에 정의된 이진법으로 변환하는 것: 인코딩
이진법을 문자 집합표에 맞게 문자로 바꾸는 것: 디코딩
아스키코드
문자 집합의 한 형태이다. 8비트로 표현되는 콤팩트한 문자집합이고, 1비트는 에러플래그를 잡는 용도이기에 2^7개만 표현 가능. 숫자, 알파벳, 특수명령, 및 일부 특수문자들 밖에 표현 못한다.
EUC-KR
초창기 문자집합인 아스키코드로는 각 나라 국가들의 글자를 표현할 수 없었기에 여러 문자집합들이 난립한다. 그중 한글은 EUC-KR이 등장
문자집합을 만들 때 아스키코드 같은 방식으로 2진법-문자 1대 1 대응으로 만드는 방식이 존재하는데 이는 완성형 인코딩 방식이라고 표현한다.
EUC-KR은 2바이트 완성형 인코딩 방식이다. 그래서 일부 한글로 만들 수 있는 괴상한 문자들을 표현 못하는 단점이 있다.
UTF-8
오늘날 가장 보편적인 유니코드 인코딩 방식이다. 사실 조합형 인코딩 방식이라 부르는 게 맞고 조합형 인코딩 방식 중에 가장 유명한 게 유니코드 인코딩 방식이라 해야 된다.
조합형은 초성, 중성, 종성 등으로 비트열을 각각 나눠놓고 모든 경우의 수를 문자집합으로 만드는 완성형과 달리 각 초성 경우의 수 중성 경우의 수 종성 경우의 수를 문자집합으로 만들어놓고 이를 조합하여 2진수를 만드는 방식이다.
조합형 인코딩 방식인 유니코드 인코딩 방식은 여러 나라 국가들의 다양한 글자 및 모든 특수문자들도 전부 표현 가능한 건 조합형이기 때문이다.
UTF-8은 총 8비트부터 4*8비트인 32비트까지 가변길이 인코딩 방식이다.
구체적으로 동작하는 원리는 책이나 검색으로 확인. 따로 정리 안 함
마무리
문자집합
컴퓨터가 표현하는 0 1 0 1 이진수 데이터를 어떻게 문자로 해석하고 저장할지를 약속한 것
아스키코드
초창기 문자집합의 한 종류. 크기는 1바이트 표현 가짓수는 2^7가지. 숫자와 알파벳은 정의가 되어 있지만, 다른 나라 글자나 특수문자를 다양하게 쓰려면 불가능하다.
EUC-KR
한글을 표현하기 위해 만들어진 대표적인 인코딩 방식. 완성형 인코딩 방식이다. 2바이트
유니코드
여러 글자 및 특수기호들을 표현하기 위해 만들어진 인코딩 방식. 조합형 인코딩 방식이다. 대표적인 UTF-8 인코딩 방식은 1~4바이트 가변길이를 가짐.
확인문제
1. 104 111 110 103 111 110 103 -> hongong
2. 2
3. UTF-8 한글 공식: 1110xxxx 10xxxxxx 10xxxxxx
c548 = 1100 0101 0100 1000 -> 11101100 10010101 10001000
b155 = 1011 0001 0101 0101 -> 11101011 10000101 10010101
ch03 명령어
큰 주제: 명령어란? 그래서 컴퓨터를 어떻게 작동시키는지
학습목표
고급 언어와 저급 언어의 차이를 이해
컴파일 언어와 인터프리터 언어의 차이를 이해
명령어를 구성하는 연산 코드와 오퍼랜드에 대해 학습
명령어의 주소 지정 방식에 대해 학습
03-1 소스 코드와 명령어
프로그래머가 짜는 코드는 소스코드
소스 코드는 명령어가 아니다.
cpu는 명령어와 데이터만 이해할 수 있다.
따라서 소스코드를 기계가 이해 가능한 언어로 바꾸는 과정이 필요하다.
고급언어와 저급언어
소스코드를 작성하기 위한 언어는 고급 언어 high level programming language
컴퓨터가 이해하기 위한 언어는 기계어
기계어는 저급언어.
저급언어의 종류는 2가지. 기계어와 어셈블리어.
어셈블리어는 기계어를 그래도 절차에 맞춰 사람이 이해가능한 정도의 단어로 변환된 언어
어셈블리어가 왜 필요하나? 기계어로 다이렉트로 가버리고 중간 과정이 없다면 실제 기계 명령어 동작의 오류를 확인할 방법이 존재하질 않기 때문.
그래서 대부분은 고급언어 -> 어셈블리어 -> 기계어의 형태 변환을 취하고 있음
컴파일 언어와 인터프리터 언어
컴파일: 고급언어를 저급언어로. 프로그램 전체 코드를 탐색하여 한번에 저급언어화
인터프리트: 고급언어를 저급언어로. 프로그램 런타임과 동시에 한 줄씩 저급언어화
컴파일러: 컴파일을 하는 놈
인터프리터: 인터프리트를 하는 놈
컴파일 언어: 컴파일로 돌아가는 언어
인터프리터 언어: 인터프리터로 돌아가는 언어
딱 칼같이 나눠질까? NO 현대 언어는 2가지 장점을 다 채용하는 방식으로 돌아가고 있음.
JAVA는 컴파일 빌드와 JVM 인터프리터 2가지 다 쓰고
파이썬 또한 컴파일을 아예 안 하는 게 아니다.
자바스크립트도 인터프리터로 돌아가지만 캐싱화하여 컴파일언어의 장점인 속도를 챙긴다.
목적코드 object code 목적 파일 object file
main.c를 컴파일한 결과 main.o 이게 목적파일이다. 목적파일은 목적코드로 이루어져 있다.
목적파일 뭉티기 만으로는 바로바로 실행이 안된다. 해당 목적파일들을 자연스럽게 연결해 주는 링커의 도움을 받아야 비로소 프로세스는 정상적으로 돌아간다.
즉
-> 소스파일 -> 컴파일(컴파일러)
-> 목적파일 -> 링크(링커)
-> 실행파일
마무리 직접
고급 언어
사람이 이해하고 쓰는 절차적 객체지향적 프로그래밍을 위한 언어
저급 언어
기계가 이해할 수 있는 흐름화가 진행된 언어
기계어
0과 1로 이루어진 쌩짜 CPU를 위한 언어
어셈블리어
기계어를 그래도 사람답게 이해할 수 있게 만들어는 놓은 언어
컴파일 언어
컴파일러에 의해 전체가 저급언어로 확실하게 변환된 뒤에 실행할 수 있는 언어
인터프리터 언어
인터프리터에 의해 실행과 동시에 한 줄씩 실행해 가며 저급언어로 변환하는 언어
확인 문제
03-2 명령어의 구조
연산 코드와 오퍼랜드
영어 명령어의 구조: 동사 + 간접목적어 +직접목적어 + 보어 + 수식어구
컴퓨터 명령어의 구조: 연산코드 + 오퍼랜드 1 + 오퍼랜드 2+ 오퍼랜드 3
연산코드는 동작을 정의하고 있음
오퍼랜드는 대상을 정의하고 있음
오퍼랜드에 대상은 실제 연산에 사용되는 대상 데이터일 수도 있고, 대상 데이터를 가리키는 주소가 저장될 수도 있다. 일반적으로 주소를 저장하는 형태로 구현되어 있고, 해당 방법이 장점이 많다.
연산코드는 크게 4가지 동작으로 나누어짐.
- 데이터 전송
- 산술/논리 연산
- 제어 흐름 변경
- 입출력 제어
주소지정방식
앞서 오퍼랜드에 주소가 저장될 수 있다고 했는데 이거와 관련해서 주소지정방식을 나누고 있다.
실제 오퍼랜드는 주소 필드라고 한다. 주소 필드에 어떻게 무엇을 지정할지에 따라 나누기에 주소 지정 방식이라고 명명된다.
- 즉시 주소 지정 방식: 오퍼랜드에 데이터 직접 넣는 거
- 직접 주소 지정 방식: 오퍼랜드에 유효데이터 주소. 유효데이터 주소로 가면 바로 다이렉트 사용할 데이터 있음
- 간접 주소 지정 방식: 오퍼랜드에 유효주소의 주소를 넣었음 두 다리 걸쳐
- 레지스터 주소 지정 방식: 오퍼랜드에 레이스터 주소를 넣고, 레지스터는 데이터를 가지고
- 레지스터 간접 주소 지정 방식: 오퍼랜드에 레지스터 주소 넣고, 레지스터는 유효 주소를 가지고
스택과 큐
스택 : LIFO
프로세스의 동작은 스택방식으로 돌아간다. 해야 할 동작을 호출호출해 가며 계속해서 쌓고 쌓인 요청들이 처리되며 비로소 하나의 동작을 완성함
큐 : FIFO
프로세스의 속도 효율을 높이기 위해서는 멀티 스레딩이 필요한데 멀티 스레딩 관리는 큐 개념이다.
마무리 직접
명령어
데이터를 이용하여 직접적으로 어떻게 처리할지를 결정하는 바이너리 코드
연산 코드
명령어의 일부 동사역할을 함.
오퍼랜드
명령어의 일부 목적어 역할을 함
주소 지정방식
주소지정방식에 따라 명령어의 오퍼랜드들을 어떻게 해석할지를 결정함.
확인 문제
2. 6번지 200이라는 값
| 1주차 (1/6 ~ 1/12) |
Chapter 01 ~ 03 | p. 51의 확인 문제 3번, p. 65의 확인 문제 3번 풀고 인증하기 |
p. 100의 스택과 큐의 개념을 정리하기 |
'Learn > 혼자 공부하는 컴퓨터구조 운영체제' 카테고리의 다른 글
| [혼공컴운][3주차] CH06~08 메모리, 캐시메모리, 보조기억장치, 입출력장치 (1) | 2025.02.04 |
|---|---|
| [혼공컴운] [2주차] CPU의 작동원리, CPU 성능 향상 기법 (0) | 2025.01.20 |